2.3 map的实现
Go中的map在底层是用哈希表实现的,你可以在 $GOROOT/src/pkg/runtime/hashmap.goc 找到它的实现。
数据结构
哈希表的数据结构中一些关键的域如下所示:
struct Hmap
{
uint8 B; // 可以容纳2^B个项
uint16 bucketsize; // 每个桶的大小
byte *buckets; // 2^B个Buckets的数组
byte *oldbuckets; // 前一个buckets,只有当正在扩容时才不为空
};上面给出的结构体只是Hmap的部分的域。需要注意到的是,这里直接使用的是Bucket的数组,而不是Bucket*指针的数组。这意味着,第一个Bucket和后面溢出链的Bucket分配有些不同。第一个Bucket是用的一段连续的内存空间,而后面溢出链的Bucket的空间是使用mallocgc分配的。
这个hash结构使用的是一个可扩展哈希的算法,由hash值mod当前hash表大小决定某一个值属于哪个桶,而hash表大小是2的指数,即上面结构体中的2^B。每次扩容,会增大到上次大小的两倍。结构体中有一个buckets和一个oldbuckets是用来实现增量扩容的。正常情况下直接使用buckets,而oldbuckets为空。如果当前哈希表正在扩容中,则oldbuckets不为空,并且buckets大小是oldbuckets大小的两倍。
具体的Bucket结构如下所示:
struct Bucket
{
uint8 tophash[BUCKETSIZE]; // hash值的高8位....低位从bucket的array定位到bucket
Bucket *overflow; // 溢出桶链表,如果有
byte data[1]; // BUCKETSIZE keys followed by BUCKETSIZE values
};其中BUCKETSIZE是用宏定义的8,每个bucket中存放最多8个key/value对, 如果多于8个,那么会申请一个新的bucket,并将它与之前的bucket链起来。
按key的类型采用相应的hash算法得到key的hash值。将hash值的低位当作Hmap结构体中buckets数组的index,找到key所在的bucket。将hash的高8位存储在了bucket的tophash中。注意,这里高8位不是用来当作key/value在bucket内部的offset的,而是作为一个主键,在查找时对tophash数组的每一项进行顺序匹配的。先比较hash值高位与bucket的tophash[i]是否相等,如果相等则再比较bucket的第i个的key与所给的key是否相等。如果相等,则返回其对应的value,反之,在overflow buckets中按照上述方法继续寻找。
整个hash的存储如下图所示(临时先采用了XX同学画的图,这个图有点问题):
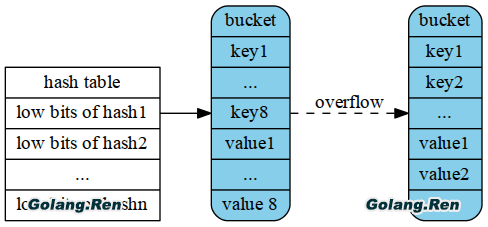
图2.2 HMap的存储结构
注意一个细节是Bucket中key/value的放置顺序,是将keys放在一起,values放在一起,为什么不将key和对应的value放在一起呢?如果那么做,存储结构将变成key1/value1/key2/value2… 设想如果是这样的一个map[int64]int8,考虑到字节对齐,会浪费很多存储空间。不得不说通过上述的一个小细节,可以看出Go在设计上的深思熟虑。
增量扩容
大家都知道哈希表表就是以空间换时间,访问速度是直接跟填充因子相关的,所以当哈希表太满之后就需要进行扩容。
如果扩容前的哈希表大小为2^B,扩容之后的大小为2^(B+1),每次扩容都变为原来大小的两倍,哈希表大小始终为2的指数倍,则有(hash mod 2^B)等价于(hash & (2^B-1))。这样可以简化运算,避免了取余操作。
假设扩容之前容量为X,扩容之后容量为Y,对于某个哈希值hash,一般情况下(hash mod X)不等于(hash mod Y),所以扩容之后要重新计算每一项在哈希表中的新位置。当hash表扩容之后,需要将那些旧的pair重新哈希到新的table上(源代码中称之为evacuate), 这个工作并没有在扩容之后一次性完成,而是逐步的完成(在insert和remove时每次搬移1-2个pair),Go语言使用的是增量扩容。
为什么会增量扩容呢?主要是缩短map容器的响应时间。假如我们直接将map用作某个响应实时性要求非常高的web应用存储,如果不采用增量扩容,当map里面存储的元素很多之后,扩容时系统就会卡往,导致较长一段时间内无法响应请求。不过增量扩容本质上还是将总的扩容时间分摊到了每一次哈希操作上面。
扩容会建立一个大小是原来2倍的新的表,将旧的bucket搬到新的表中之后,并不会将旧的bucket从oldbucket中删除,而是加上一个已删除的标记。
正是由于这个工作是逐渐完成的,这样就会导致一部分数据在old table中,一部分在new table中, 所以对于hash table的insert, remove, lookup操作的处理逻辑产生影响。只有当所有的bucket都从旧表移到新表之后,才会将oldbucket释放掉。
扩容的填充因子是多少呢?如果grow的太频繁,会造成空间的利用率很低, 如果很久才grow,会形成很多的overflow buckets,查找的效率也会下降。 这个平衡点如何选取呢(在go中,这个平衡点是有一个宏控制的(#define LOAD 6.5), 它的意思是这样的,如果table中元素的个数大于table中能容纳的元素的个数, 那么就触发一次grow动作。那么这个6.5是怎么得到的呢?原来这个值来源于作者的一个测试程序,遗憾的是没能找到相关的源码,不过作者给出了测试的结果:
LOAD %overflow bytes/entry hitprobe missprobe
4.00 2.13 20.77 3.00 4.00
4.50 4.05 17.30 3.25 4.50
5.00 6.85 14.77 3.50 5.00
5.50 10.55 12.94 3.75 5.50
6.00 15.27 11.67 4.00 6.00
6.50 20.90 10.79 4.25 6.50
7.00 27.14 10.15 4.50 7.00
7.50 34.03 9.73 4.75 7.50
8.00 41.10 9.40 5.00 8.00
%overflow = percentage of buckets which have an overflow bucket
bytes/entry = overhead bytes used per key/value pair
hitprobe = # of entries to check when looking up a present key
missprobe = # of entries to check when looking up an absent key可以看出作者取了一个相对适中的值。
查找过程
根据key计算出hash值。
如果存在old table, 首先在old table中查找,如果找到的bucket已经evacuated,转到步骤3。 反之,返回其对应的value。
在new table中查找对应的value。
这里一个细节需要注意一下。不认真看可能会以为低位用于定位bucket在数组的index,那么高位就是用于key/valule在bucket内部的offset。事实上高8位不是用作offset的,而是用于加快key的比较的。
do { //对每个桶b
//依次比较桶内的每一项存放的tophash与所求的hash值高位是否相等
for(i = 0, k = b->data, v = k + h->keysize * BUCKETSIZE; i < BUCKETSIZE; i++, k += h->keysize, v += h->valuesize) {
if(b->tophash[i] == top) {
k2 = IK(h, k);
t->key->alg->equal(&eq, t->key->size, key, k2);
if(eq) { //相等的情况下再去做key比较...
*keyp = k2;
return IV(h, v);
}
}
}
b = b->overflow; //b设置为它的下一下溢出链
} while(b != nil);插入过程分析
根据key算出hash值,进而得出对应的bucket。
如果bucket在old table中,将其重新散列到new table中。
在bucket中,查找空闲的位置,如果已经存在需要插入的key,更新其对应的value。
根据table中元素的个数,判断是否grow table。
如果对应的bucket已经full,重新申请新的bucket作为overbucket。
将key/value pair插入到bucket中。
这里也有几个细节需要注意一下。
在扩容过程中,oldbucket是被冻结的,查找时会在oldbucket中查找,但不会在oldbucket中插入数据。如果在oldbucket是找到了相应的key,做法是将它迁移到新bucket后加入evalucated标记。并且还会额外的迁移另一个pair。
然后就是只要在某个bucket中找到第一个空位,就会将key/value插入到这个位置。也就是位置位于bucket前面的会覆盖后面的(类似于存储系统设计中做删除时的常用的技巧之一,直接用新数据追加方式写,新版本数据覆盖老版本数据)。找到了相同的key或者找到第一个空位就可以结束遍历了。不过这也意味着做删除时必须完全的遍历bucket所有溢出链,将所有的相同key数据都删除。所以目前map的设计是为插入而优化的,删除效率会比插入低一些。
map设计中的性能优化
读完map源代码发现作者还是做了很多设计上的选择的。本人水平有限,谈不上优劣的点评,这里只是拿出来与读者分享。
HMap中是Bucket的数组,而不是Bucket指针的数组。好的方面是可以一次分配较大内存,减少了分配次数,避免多次调用mallocgc。但相应的缺点,其一是可扩展哈希的算法并没有发生作用,扩容时会造成对整个数组的值拷贝(如果实现上用Bucket指针的数组就是指针拷贝了,代价小很多)。其二是首个bucket与后面产生了不一致性。这个会使删除逻辑变得复杂一点。比如删除后面的溢出链可以直接删除,而对于首个bucket,要等到evalucated完毕后,整个oldbucket删除时进行。
没有重用设freelist重用删除的结点。作者把这个加了一个TODO的注释,不过想了一下觉得这个做的意义不大。因为一方面,bucket大小并不一致,重用比较麻烦。另一方面,下层存储已经做过内存池的实现了,所以这里不做重用也会在内存分配那一层被重用的,
bucket直接key/value和间接key/value优化。这个优化做得蛮好的。注意看代码会发现,如果key或value小于128字节,则它们的值是直接使用的bucket作为存储的。否则bucket中存储的是指向实际key/value数据的指针,
bucket存8个key/value对。查找时进行顺序比较。第一次发现高位居然不是用作offset,而是用于加快比较的。定位到bucket之后,居然是一个顺序比较的查找过程。后面仔细想了想,觉得还行。由于bucket只有8个,顺序比较下来也不算过分。仍然是O(1)只不过前面系数大一点点罢了。相当于hash到一个小范围之后,在这个小范围内顺序查找。
插入删除的优化。前面已经提过了,插入只要找到相同的key或者第一个空位,bucket中如果存在一个以上的相同key,前面覆盖后面的(只是如果,实际上不会发生)。而删除就需要遍历完所有bucket溢出链了。这样map的设计就是为插入优化的。考虑到一般的应用场景,这个应该算是很合理的。
作者还列了另个2个TODO:将多个几乎要empty的bucket合并;如果table中元素很少,考虑shrink table。(毕竟现在的实现只是单纯的grow)。