
ES 与SOLR
1.Solr在查询固定数据时,速度相对ES更快一些,但是数据如果是实时改变的,Solr的查询速度会降低很多,Es的查询的效率基本没有变化
2.Solr搭建基于需要依赖 Zookeeper来帮助管理,ES本身就支持集群的搭建,不需要第三方的介入
3.最开始Solr的社区可以说是非常火爆,针对国内的文档井不是很多,在ES出现之后,ES的社区火爆程度, 直线上升,Es的文档非常健全
4.ES对现在云计算和大数据支持的特别好
倒排序
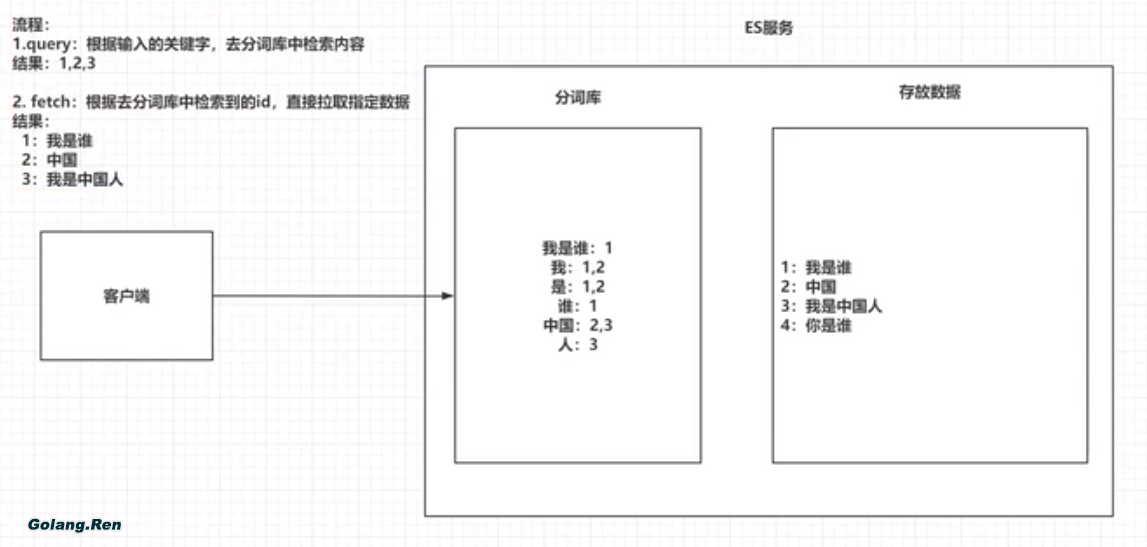
将存放的数据,以一定的方式进行分词,并且将分词的内容存放到一个单独的分词库中
当用户去查询数据时,会将用户的查询关键字进行分词
然后去分词库中匹配内容,最终得到数据的d标识
根据d标识去存放数据的位置拉取到指定的数据
安装
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.6.2-linux-x86_64.tar.gz #下载
tar -zxvf elasticsearch-7.6.2-linux-x86_64.tar.gz #解压
cd elasticsearch-7.6.2
bin/elasticsearch 配置
elasticsearch.yml
| 配置项 | 备注 |
|---|---|
| node.name | 节点名称 打开 |
| network.host | 监听ip,打开 0.0.0.0 |
| discovery.seed_hosts | 初始服务器ip "127.0.0.1" |
| cluster.initial_master_nodes | 主节点 打开 |
| cluster.name | 集群组名称 |
jvm.options
| 项目 | 说明 |
|---|---|
| -Xms256m | 初始内存大小 |
| -Xmx256m | 最大内存大小 |
报错解决
- 错误:Exception in thread "main" java.lang.RuntimeException: don't run elasticsearch as root.
原因:我们在使用elasticsearch的时候,如果是以root权限来执行elasticsearch则会报错,这是出于系统安全考虑设置的条件。由于ElasticSearch可以接收用户输入的脚本并且执行,为了系统安全考虑, 建议创建一个单独的用户用来运行ElasticSearch
解决:
groupadd elsearch #创建elsearch用户组及elsearch用户
useradd elsearch -g elsearch -p elasticsearch #创建elsearch用户
chown -R elsearch:elsearch elasticsearch-7.6.2 #更改elasticsearch文件夹及内部文件的所属用户及组为elsearch:elsearch
su elsearch #切换账户
cd elasticsearch-7.6.2/bin #进入你的elasticsearch目录下的bin目录
./elasticsearch -d #启动
ps aux|grep elasticsearch #查看是否正常运行
- 错误:max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
原因:elasticsearch用户拥有的内存权限太小,至少需要262144;
解决:切换到root用户,执行命令:
sysctl -w vm.max_map_count=262144 #查看结果:
sysctl -a|grep vm.max_map_count #显示:
vm.max_map_count = 262144 #上述方法修改之后,如果重启虚拟机将失效,所以:
解决办法:
在 /etc/sysctl.conf文件最后添加一行
vm.max_map_count=262144
即可永久修改ES与mysql对应关系
| mysql | ES |
|---|---|
| 数据库 | Index |
| 表 | type (6以后已经作废) |
| 一行记录 | Document |
| 列 | Field |
| Schema约束 | mapping |
| 索引 | |
| SQL语句 | Query DSL |
| Select * from table | GET http://... |
| update table set ... | PUT http://... |
Mapping映射
创建索引时预定义字段类型和相关属性,让索引更完善,提高查询效率
ES常用字段类型
| 常用类型 | ES中type类型 | 备注 |
|---|---|---|
| string,varchar,text | text keyword |
5.x以后不再支持string text 类型:当一个字段是要被全文搜索的,比如Email内容、产品描述,应该使用text类型。设置text类型以后,字段内容会被分析,在生成倒排索引以前,字符串会被分析器分成一个一个词项。text类型的字段不用于排序,很少用于聚合。 keyword类型适用于索引结构化的字段,比如email地址、主机名、状态码和标签。如果字段需要进行过滤(比如查找已发布博客中status属性为published的文章)、排序、聚合。keyword类型的字段只能通过精确值搜索到。 |
| integer | byte short integer long |
|
| float,double | float double half_float scaled_float |
32位单精度IEEE 754浮点类型 64位双精度IEEE 754浮点类型 16位半精度IEEE 754浮点类型 缩放类型的的浮点数 |
| boolean | boolean | true和false |
| date/datetime | date | 1. 日期格式的字符串,比如 “2018-01-13” 或 “2018-01-13 12:10:30” 2. long类型的毫秒数( milliseconds-since-the-epoch,epoch就是指UNIX诞生的UTC时间1970年1月1日0时0分0秒) 3. integer的秒数(seconds-since-the-epoch) |
| bytes/binary | binary | 进制字段是指用base64来表示索引中存储的二进制数据,可用来存储二进制形式的数据,例如图像。默认情况下,该类型的字段只存储不索引。二进制类型只支持index_name属性。 |
| array | array | 1. 字符数组: [ “one”, “two” ] 2. 整数数组: productid:[ 1, 2 ] 3. 对象(文档)数组: “user”:[ { “name”: “Mary”, “age”: 12 }, { “name”: “John”, “age”: 10 }], 注意:elasticSearch不支持元素为多个数据类型:[ 10, “some string” ] |
| object | JSON对象,文档会包含嵌套的对象 | |
| ip | ip类型的字段用于存储IPv4或者IPv6的地址 |
Mapping 支持属性
| 属性 | 描述 | 适用字段类型 |
|---|---|---|
| store | 是否单独设置此字段的是否存储而从_source字段中分离,只能搜索,不能获取值 "store": false(默认)true |
all |
| index | 是否构建倒排索引(即是否分词,设置false,字段将不会被索引) "index": true(缺省)false |
string |
| null_value | 设置一些缺失字段的初始化,只有string可以使用,分词字段的null值也会被分词 "null_value": "NULL" |
string |
| boost | 检索时,字段级优先权重,默认值是1.0 "boost": 1.23 |
all |
| search_analyzer | 设置搜索时的分词器,默认跟analyzer是一致的,比如index时用standard+ngram,搜索时用standard用来完成自动提示功能 "search_analyzer": "ik" |
text |
| analyzer | 指定分词器,默认分词器为standard analyzer "analyzer": "ik" |
text |
| include_in_all | all | |
| index_name | all | |
| norms | 是否归一化相关参数、如果字段仅用于过滤和聚合分析、可关闭 分词字段默认配置,不分词字段:默认{“enable”: false},存储长度因子和索引时boost,建议对需要参加评分字段使用,会额外增加内存消耗 "norms": {"enable": true, "loading": "lazy"} |
all |
更多参考 https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-params.html
PUT /store
{
"mappings":{
"properties":{
"title":{
"type":"keyword"
},
"price":{
"type":"integer"
}
}
}
}中文分词
下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
安装插件:把插件包 elasticsearch-analysis-ik(需要mvn编译过)解压到 elasticsearch\plugins\ik目录下,后启动ES 自动识别
测试分词
POST _analyze
{
"analyzer": "ik_smart",
"text": "我是一个程序员"
}创建mapping 分词只能用于text类型
PUT /store
{
"mappings":{
"properties":{
"title":{
"type":"text",
"analyzer":"ik_max_word",
"search_analyzer":"ik_max_word"
},
"price":{
"type":"integer"
}
}
}
}使用方法
访问方式
http://ip:9200/index/type/[id]
#api格式
curl -H "ContentType:application/json" -X PUT 127.0.0.1:9200/index -d '
{
"settings":{
"number_of_shards":1,
"number_of_replicas":0
}
}'
#命令行格式
PUT /index
{
"settings":{
"number_of_shards":1,
"number_of_replicas":0
}
}查看健康状态
curl -X GET 127.0.0.1:9200/_cat/health?v查询当前es集群中所有的indices
curl -X GET 127.0.0.1:9200/_cat/indices?v创建初始化索引
PUT /store
{
"settings":{
"number_of_shards":1, //分片数量
"number_of_replicas":0 //备份数量
},
"mappings":{
"properties":{
"title":{
"type":"text",
"analyzer":"ik_max_word"
},
"price":{
"type":"integer"
}
}
}
}
#blocks.read_only:true //只读
#blocks.read:true //禁止读
#blocks.write:true //禁止写
#blocks.metadata:true //禁止操作metadata
向已有索引中添加新字段
POST /store/_mappings
{
"properties":{
"status":{
"type":"integer"
}
}
}
不支持删除或更新某个字段
获取索引配置
GET /store/_settings //获取配置
GET /index1,index2/_settings //获取2个索引配置
GET /_all/_settings //获取所有配置删除记录
DELETE /store 索引
DELETE /index/_doc/id 记录删除条件记录
据term, match等查询方式去删除大量的文档 GET /store/_search替换成POST /store/_doc/_delete_by_query
Ps:如果需要删除的内容,是index下的大部分数据,推荐创建一个全新的index,将保留的文档内容,添加到全新的索引
POST /store/_doc/_delete_by_query
{
query:条件
}插入记录
使用POST时不指定id, 会自动生成uuid,不方便更新删除,不推荐
POST /store/_doc
{
"title": "php",
"price": 20,
"create_time": "2016-06-06"
}也可以使用PUT方法,但是需要传入id
PUT /store/_doc/4
{
"title": "php",
"price": 20,
"create_time": "2016-06-06"
}获取记录
GET /store/_doc/id
GET /store/_doc/id?_source=title //查询指定字段更新记录指定字段
POST /store/_update/id
{
"doc":{
"price":10
}
}
或
PUT /store/_doc/id
{
"price":50
}更新覆盖整条记录
POST /store/_doc/id
{
"title": "php",
"price": 20,
"create_time": "2016-06-06"
}批量获取
GET /_mget
{
"docs":[
{
"_index" : "store",
"_type" : "book",
"_id" : 3
"_source":"price" //可指定字段,多个用数组形式 []
},
{
"_index" : "store",
"_type" : "book",
"_id" : 4
}
]
}
//获取同一个索引同一个type下不同id
GET /store/_mget
{
"ids":["3","4"]
}Bulk批量CURD
| 行为 | 备注 |
|---|---|
| create | 文档不存在时创建 |
| index | 创建新文档或替换已有文档 |
| update | 局部更新 |
| delete | 删除文档 |
{action:{metadata}}\n
{requestbody}\n批量新增加
POST /store/_bulk
{"index":{"_id":1}}
{"title":"php是世界上最好的语言","price":30}
{"index":{"_id":2}}
{"title":"java是世界上最难的语言","price":20}
{"index":{"_id":3}}
{"title":"python是人工智能语言","price":35}批量删除
POST /store/_bulk
{"delete":{"_id":1}}批量更新
POST /store/_bulk
{"update":{"_id":2}}
{"doc":{"price":12}}版本控制
版本控制用于乐观锁,内部版本控制:(version已被7淘汰,7使用if_seq_no 和 if_primary_term)
PUT /store/_doc/1?if_seq_no=0&if_primary_term=1
{
"price":50
}版本控制用于乐观锁,外部版本控制,更新时外部版本号不得小于内部版本号:
PUT /store/_doc/1?version=4&version_type=external
{
"price":50
}检索查询
Elasticsearch的检索语法比较特别,使用GET方法携带JSON格式的查询条件。
全检索:
curl -X GET 127.0.0.1:9200/store/_doc/_search按条件检索:
_search: 查询
query:查询条件
bool:聚合查询组合条件 相当于()
must:必须满足 相当于and =
should:条件可以满足 相当于or
must_not:条件不需要满足,相当于and not
range:范围
gt: 大于
lt:小于
gte:大等于
lte:小等于
filter:条件过滤
term:不分词
普通查询
分页查询相当于limit
from和size 之合不能超过10000
GET /store/_search
{
"from":0,
"size":10
}使用term查询
term查询不会对指定关键词进行分词,而是从分词库中匹配
相当于 where title ="java"
GET /store/_search
{
"query":{
"term":{
"title":"java"
}
}
}使用terms查询查询多个值
相当于 where title in ("php","java")
GET /store/_search
{
"query":{
"terms": {
"title":["php","java"]
}
}
}match高级查询
match查询属于高层查询,他会根据你查询的字段类型不一样,采用不同的查询方式。
-
查询的是日期或者是数值的话,他会将你基于的字符串查询内容转换为日期或者数值对待。
-
如果查询的内容是一个不能被分词的内容( keyword), match查询不会对你指定的查询关键字进行分词
-
如果查询的内容时一个可以被分词的内容(text), match会将你指定的查询内容根据一定的方式去分词,去分词库中匹配指定的内容。
match查询,实际底层就是多个term查询,将多个term查询的结果给你封装到了一起
默认查询10条记录
GET /store/_search
{
"query":{
"match": {
"title":"php"
}
}
}
match_all查询,返回所有数据,不指定查询条件
GET /store/_search
{
"query":{
"match_all": {}
}
}match_phrase查询,短语查询,slop定义关键词之间间隔多少未知单词 用逗号或空格间隔多个关键词
GET /store/_search
{
"query":{
"match_phrase": {
"title":{
"query":"p,p",
"slop":2
}
}
}
}布尔match 基于一个字段,采用and或or的条件查询 用逗号或空格间隔多个关键词
GET /store/_search
{
"query":{
"match": {
"title":{
"query":"php java python",
"operator":"or"
}
}
}
}multi_match查询 基于多个字段查询一个关键词
GET /store/_search
{
"query":{
"multi_match": {
"query":"php",
"fields":["title"]
}
}
}其他查询
查询效率较低
perfix 前缀查询
类似 like "key%"
GET /store/_search
{
"query":{
"prefix": {
"title":"php"
}
}
}fuzzy相似查询
具有容错性
GET /store/_search
{
"query":{
"fuzzy": {
"title":{
"value":"php",
"prefix_length":3 //可选,前三个不允许错
}
}
}
}wildcard查询
通配符 ? 或 *,?占一个字符
GET /store/_search
{
"query":{
"wildcard": {
"title":{
"value":"p??"
}
}
}
}range查询
范围查询只针对数值 where (price>=20 and price <30) 符号 gt,gte,lt,lte
GET /store/_search
{
"query":{
"range": {
"price":{
"gte":20,
"lt":30
}
}
}
}regexp正则查询
GET /store/_search
{
"query":{
"regexp": {
"title":"[a-p]h.*?"
}
}
}深分页scroll
ES对from+size是有限制的,from和size二者之和不能超过1W
from+size ES查询数据的方式:
- 第一步现将用户指定的关键进行分词
- 第二步将词汇去分词库中进行检索,得到多个文档的id
- 第三步去各个分片中去拉取指定的数据,耗时较长
- 第四步将数据根据 score进行排序
- 第五步根据from的值,将查询到的数据舍弃一部分
- 第六步返回结果
scroll查询数据方式
-
第一步现将用户指定的关键进行分词
-
第二步将词汇去分词库中进行检索,得到多个文档的id
-
第三步将文档的d存放在一个Es的上下文中
-
第四步根据你指定的size的个数去Es中检索指定个数的数据,拿完数据的文档id,会从上下文中移
-
第五步如果需要下一页数据,直接去ES的上下文中,找后续内容
Scroll查询方式,不适合做实时的查询
GET /store/_search?scroll=1m
{
"query":{
"match_all": {
}
},
"size":2,
"sort":[{
"price":{
"order":"desc"
}
}]
}查询结果中的 scroll_id 是内存上下文id, 用id查询下一页
GET /_search/scroll
{
"scroll_id":"",
"scroll":"1m"
}删除scroll
DELETE /_search/scroll/FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFERCUjRxM1VCS3gxSGNZVURIWWRJAAAAAAAAC5sWUmprMWhGYUpSNUd2X25paTg2RVROdw==
组合查询
bool查询
复合过滤器,将你的多个查询条件,以一定的逻辑组合在一起
must:所有的条件,用mus组合在一起,表示and true的意思
must not:将 must not中的条件,全部都不能匹配,标识and not true的意思
should:所有的条件,用 should组合在一起,表示or true的意思
例如 select * from store where (price=20 or price =30) and create_time <>"2016-06-06"
{
"query":{
"bool": {
"should":[
{"term":{"price":20}},
{"term":{"price":30}}
],
"must_not":{
"term":{"create_time":"2016-06-06"}
}
},
}
}boosting 查询
boosting查询可以帮助我们去影响查询后的 score
- positive:只有匹配上 positive的意询的内容,才会被放到返回的结果集中
- negative:如果匹配上和 positive并且也匹配上了 negative,就可以降低这样的文档 score
- negative boost:指定系数,必须小于1.0 系数会乘上score 降低排名
关于查询时,分数是如何计算的
- 搜索的关键字在文档中出现的频次越高,分数就越高
- 指定的文档内容越短,分数就越高
- 我们在搜索时,指定的关键字也会被分词,这个被分词的内容,被分词库匹配的个数越多,分数越高
GET /store/_search
{
"query":{
"boosting":{
"positive":{
"match": {
"title": "java"
}
},
"negative": {
"match": {
"title": "y"
}
},
"negative_boost": 0.2
}
}
}filter查询
query,根据你的查询条件,去计算文档的匹配度得到一个分数,并且根据分数进行排序,不会做缓存的
filter,根据你的查询条件去查询文档,不去计算分数,而且filter会对经常被过滤的数据进行缓存
GET /store/_search
{
"query":{
"bool":{
"filter":[
{
"term":{
"title":"java"
}
},
{
"term":{
"price":20
}
}
]
}
}
}高亮查询
高亮查询就是你用户输入的关键字,以一定的特殊样式展示给用户,让用户知道为什么这个结果被检索出来
高亮展示的数据,本身就是文档中的一个Feld,单独将 FieldlAhighlight的形式返回给你
ES提供了一个 highlight属性,和 query同级别的
fields:指定哪些字段按高亮返回
fragment_size:指定高亮数据展示多少个字符回来
pre_tags:指定前缀标签
post_tags:指定后缀标签
GET /store/_search
{
"query":{
"term":{
"title":"java"
}
},
"highlight":{
"fields":{
"title":{}
},
"pre_tags":"<font color=red>",
"post_tags":"</font>",
"fragment_size":4
}
}
聚合查询
ES的聚合查询和MYSQL的聚合查询类型,ES的聚合查询相比Mysql要强大的多,ES提供的统计数据的方式多种多样
GET /store/_search
{
"aggs":{
"agg":{ //名字
”agg_type":{
"" //属性:值
}
}
}
}去重计数查询
GET /store/_search
{
"aggs":{
"agg":{ //名字
"cardinality":{
"field":"price"
}
}
}
}范围统计
统计一定范围内出现的文档个数,比如,针对某一个Feld的值在0-100,100-200, 200-300之间文档出现的个数分别是多少
范围统计可以针对普通的数值,针对时间类型,针对类型都可以做相应的统计.
range , data_range, ip_range
GET /store/_search
{
"aggs":{
"agg":{
"range":{
"field": "price",
"ranges": [
{"from": 10,"to":50}
]
}
}
}统计聚合
他可以帮你查询指定Fed的最大值,最小值,平均值,平方和,,,
GET /store/_search
{
"aggs":{
"agg":{
"extended_stats":{
"field": "price"
}
}
}
}更多api https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-metrics.html
地图检索
geo_distance: 直线距离检索方式
geo_bounding_box: 以两个点确定一个矩形,获取在矩形内的全部数据
geo_polygon: 以多个点(至少3个点),确定一个多边形,获取多边形内的全部数据
GET /map/_search
{
"query":{
"geo_distance":{
"location":{
"lon": 123.51551, //经度
"lat": 421.215, //纬度
},
"distance":2000, // 距离米
"distance_type":"arc" //圆形范围
}
}
}GET /map/_search
{
"query":{
"geo_bounding_box":{
"location":{
"top_left": {
"lon": 123.51551, //经度
"lat": 421.215, //纬度
},
"bottom_right":{
"lon": 123.51551, //经度
"lat": 421.215, //纬度
}
}
}
}
}GET /map/_search
{
"query":{
"geo_polygon":{
"location":{
"points": [
{
"lon": 123.51551, //经度
"lat": 421.215, //纬度
},
{
"lon": 123.51551, //经度
"lat": 421.215, //纬度
},
{
"lon": 123.51551, //经度
"lat": 421.215, //纬度
}
]}
}
}
}杀死进程
kill ps -ef|grep Elasticsearch | grep -v grep|awk '{print $2}'
Kibana
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.6.2-linux-x86_64.tar.gz配置
| 配置项 | 备注 |
|---|---|
| elasticsearch.hosts: ["http://127.0.0.1:9200"] | es地址 |